#7 ️ Understanding RAG — From Memory to Real-Time Retrieval
In today’s AI landscape, language models are like students who have read many books but still need to look up information for precise answers.
In today’s AI landscape, language models are like students who have read many books but still need to look up information for precise answers. Retrieval-Augmented Generation (RAG) is an advanced technique that combines language generation with real-time information retrieval, making AI responses more accurate and contextually rich.
1. What is RAG? 🧐
RAG is a method that enhances traditional language models by integrating a retrieval layer that fetches relevant external information during response generation. It brings together the strengths of two AI approaches:
-
Language Models: Like GPTs, which generate responses based on existing internal knowledge.
-
Retrieval Models: Like search engines, which fetch external information based on queries.
Why Use RAG? 🔍
While standalone language models rely solely on pre-existing knowledge, RAG models can dynamically fetch information, making responses more accurate and up-to-date.
Imagine preparing for a quiz. You might know most answers from memory (like an LLM), but for more specific or recent questions, you need to check a textbook (like a retrieval step). RAG combines both processes, creating a smarter, more informed AI response.
2. Core Components of RAG 🔄
The RAG framework consists of three main components:
-
Embedding Layer: Converts user queries and documents into numerical vectors, capturing their semantic meaning.
-
Vector Database: Stores vectors of documents or knowledge, allowing for efficient similarity-based retrieval.
-
Language Model: Combines retrieved information with its own internal knowledge to generate a more accurate, context-aware response.
How RAG Works:
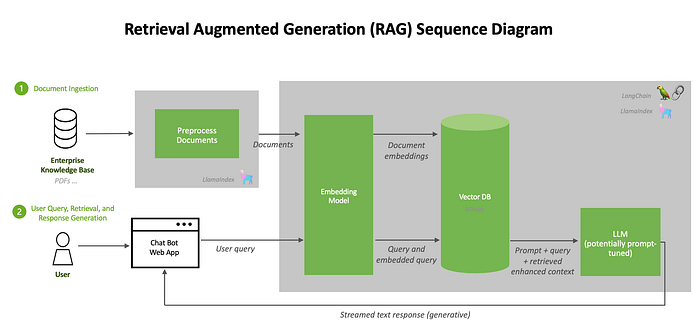
-
User Query → Embedding Layer: The user’s question is converted into a vector representation using an embedding model like OpenAI’s text-embedding-ada-002.
-
Embedding → Vector Search: The query vector is matched against vectors in the database, retrieving the most relevant information.
-
Retrieved Info → Language Model: The retrieved information is fed into the language model, which generates a more contextually accurate response.
Think of RAG as a librarian who not only remembers general knowledge but can also fetch specific books from the library to provide the best answer.
Lets dive into more details about the core components.
2.1. Embedding Layer: Converting Text to Semantic Vectors 🔢📏✨
Embeddings convert text into numerical vectors that capture semantic meaning. They enable the semantic search that’s central to RAG, as they help match user queries with similar documents based on meaning, not just keywords.
Think of embeddings as GPS coordinates for words — similar words are closer together in vector space. For example, “cat” and “kitten” would have closer vectors than “cat” and “car,” reflecting their semantic similarity.
Popular Embedding Models for RAG:
- OpenAI’s text-embedding-ada-002:
-
Strengths: High quality, versatile, optimized for semantic search, and widely used in industry.
-
Use Cases: General-purpose semantic search, customer service, and information retrieval.
-
Why Choose This Model? It offers state-of-the-art performance and is suitable for various domains, making it a common choice for RAG applications.
- Sentence Transformers (e.g., ‘all-MiniLM-L6-v2’):
-
Strengths: Efficient, open-source, and fast, making it ideal for real-time applications.
-
Use Cases: FAQ matching, document retrieval, and summarization.
-
Why Choose This Model? It’s lightweight, cost-effective, and suitable for real-time processing in resource-limited environments.
- GloVe (Global Vectors for Word Representation):
-
Strengths: Pre-trained on large corpora, capturing semantic relations between words.
-
Use Cases: Basic similarity search, topic modeling, and entity extraction.
-
Why Choose This Model? It’s simpler, more interpretable, and works well in smaller-scale retrieval tasks.
- Hugging Face Transformers:
-
Models: BERT, RoBERTa, and DistilBERT are popular choices.
-
Use Cases: Text classification, sentiment analysis, and contextual retrieval.
-
Why Choose These Models? They excel in tasks that require contextual understanding, making them useful for retrieving more nuanced information.
Imagine embeddings like different translation dictionaries — each model offers its own “dialect” of semantic understanding, so the choice depends on what language of similarity you need to interpret.
2.2. Vector Databases: Powering Fast and Efficient Retrieval 🗂️🚀
A vector database is essential in RAG to store embeddings and retrieve similar vectors efficiently. It performs semantic searches to find the closest match to a given query.
How Semantic Search Works in Vector Databases:
-
Process: When a query is embedded, the vector database finds vectors that are closest in distance (usually using cosine similarity or L2 distance).
-
Outcome: The model retrieves documents that are most relevant in terms of meaning, not just word overlap.
Think of a vector database as a search engine that understands synonyms — it can find related concepts, not just exact matches. It’s like searching for “fast car” and finding “sports car,” because both concepts are semantically close.
Popular Vector Databases for RAG:
- FAISS (Facebook AI Similarity Search):
-
Strengths: High performance, optimized for CPU and GPU, and handles large datasets well.
-
Use Cases: Real-time retrieval in chatbots, recommendation systems, and search engines.
-
Why Choose FAISS? It’s open-source, fast, and highly scalable, making it a go-to choice for many RAG implementations.
- Pinecone:
-
Strengths: Fully managed vector database with a focus on ease of use, fast retrieval, and scalability.
-
Use Cases: Real-time document search, product recommendation, and conversational AI.
-
Why Choose Pinecone? It offers managed infrastructure, so developers can focus on application logic without worrying about scaling or deployment.
- Weaviate:
-
Strengths: Open-source, supports multi-modal vectors (text, images), and integrates well with popular ML frameworks.
-
Use Cases: Knowledge management, semantic search, and data discovery.
-
Why Choose Weaviate? It’s ideal for multi-modal retrieval tasks where text and images need to be matched.
- Milvus:
-
Strengths: Open-source, built for large-scale similarity search, and offers a user-friendly interface.
-
Use Cases: Video recommendation, e-commerce search, and healthcare data retrieval.
-
Why Choose Milvus? It’s known for its performance with large-scale data, making it effective for big data applications in RAG.
If vector databases were search assistants, FAISS would be the fast and efficient expert, Pinecone the easy-to-use online helper, and Weaviate the multi-talented assistant who can search text, images, and more.
2.3. Language Models: Generating Context-Rich Responses 🤖💬
The language model in RAG combines retrieved information with its internal knowledge to generate accurate responses. Popular models for this step include GPT-3, GPT-4, and Claude.
- Example: After retrieving a document about “cotton t-shirts,” GPT-4 can generate a response like, “We have red cotton t-shirts available in sizes S, M, L, and XL, priced at $20.”
Think of the language model as a storyteller who uses both memory and newly found information to answer questions more comprehensively.
3. Advantages of RAG 🏆
- Enhanced Accuracy 🧠RAG combines general knowledge with real-time information retrieval, ensuring responses are factually correct and contextually relevant.
- **Dynamic Responses ⚡**RAG can adapt to new information quickly, making it suitable for tasks like customer service, content creation, and knowledge management.
- Scalability 📈RAG can efficiently manage large datasets and knowledge bases, making it ideal for enterprise applications that require handling diverse information.
- Versatile Applications 🌍From chatbots to research assistants, RAG enables better language understanding and response accuracy across various industries.
RAG is like a dual-mode GPS that combines preloaded maps (internal knowledge) with real-time traffic data (external retrieval), helping users navigate more effectively.
4. Detailed Example: RAG-Based Retail Customer Service Chatbot 🛒🤖
To illustrate RAG’s practical benefits, we’ll build a RAG-based chatbot for a retail company. This chatbot can:
-
Answer product-related queries with accurate information.
-
Handle customer service inquiries by retrieving real-time product data.
-
Generate human-like responses using OpenAI’s GPT.
Step 1: Set Up the Environment
Install the required libraries:
pip install openai faiss-cpu flask python-dotenv pandas transformers PyPDF2 python-docxStep 2: Loading and Preparing Product Data 🛍️
Instead of manual data entry, we’ll use structured data from a CSV file. The CSV contains product details such as names, descriptions, sizes, materials, and prices.
Example Product Data (CSV):
| Product ID | Name | Description | Price | Sizes | Material | Category |
|---|---|---|---|---|---|---|
| 101 | Red T-Shirt | Comfortable cotton t-shirt in red. | $2 0 | S, M, L, XL | Cotton | Clothing |
| 102 | Blue Jeans | Stylish blue jeans, regular fit. | $45 | 28, 30, 32, 34 | Denim | Clothing |
| 103 | Black Sneakers | Comfortable black sneakers. | $6 0 | 8, 9, 10, 11 | Synthetic | Footwear |
| 104 | Leather Wallet | Premium leather wallet. | $25 | N/A | Genuine Leather | Accessories |
| 105 | Cotton Socks | Soft cotton socks, pack of 3. | $5 | N/A | Cotton | Accessories |
Code: Load Product Data from CSV
import pandas as pd
# Load the product data from a CSV file
product_data = pd.read_csv('products.csv')
# Concatenate fields for vectorization
def prepare_product_data(row):
return f"Product: {row['Name']}, Description: {row['Description']}, Price: {row['Price']}, Sizes: {row['Sizes']}, Material: {row['Material']}, Category: {row['Category']}"
# Prepare product descriptions for embedding
product_descriptions = product_data.apply(prepare_product_data, axis=1).tolist()Step 3: Embedding Generation for Product Data 🔢
We’ll use OpenAI’s embeddings API to convert product descriptions into numerical vectors, allowing semantic search.
Code: Generate Embeddings
import numpy as np
import openai
openai.api_key = 'YOUR_API_KEY' # Replace with actual API key
def get_embedding(text):
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=text
)
return np.array(response['data'][0]['embedding'])
# Generate embeddings for all product descriptions
product_embeddings = [get_embedding(description) for description in product_descriptions]Step 4: Building the Vector Database with FAISS 🗂️
Store the embeddings in a FAISS vector database for fast and efficient retrieval.
Code: Create Vector Index
import faiss
dimension = len(product_embeddings[0])
index = faiss.IndexFlatL2(dimension)
# Add embeddings to the index
index.add(np.array(product_embeddings))Step 5: Implementing RAG-Based Retrieval and Response Generation 🛠️
RAG Retrieval Function
def retrieve_product_info(query, index, product_descriptions):
query_embedding = get_embedding(query).reshape(1, -1)
distances, indices = index.search(query_embedding, k=3) # Get top 3 matches
return [product_descriptions[idx] for idx in indices[0]]
# Example Query
query = "Do you have a cotton t-shirt?"
matched_products = retrieve_product_info(query, index, product_descriptions)
print(f"Matched Products: {matched_products}")Final Response Generation
def generate_final_response(query, matched_products):
context = "\n".join(matched_products)
prompt = f"Customer Question: {query}\nMatched Products: {context}\nAnswer:"
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
max_tokens=150
)
return response.choices[0].text.strip()
# Generate response for the user query
final_response = generate_final_response(query, matched_products)
print(f"Final Response: {final_response}")Output Example: We have a comfortable cotton T-shirt available in sizes S, M, L, and XL, priced at $20. Would you like to add it to your cart?
6. Integrating the Chatbot with Flask 💬
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/chat', methods=['POST'])
def chat():
user_query = request.json.get('query')
if not user_query:
return jsonify({"error": "No query provided"}), 400
matched_products = retrieve_product_info(user_query, index, product_descriptions)
final_response = generate_final_response(user_query, matched_products)
return jsonify({"response": final_response})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)Real-World Benefits of RAG in Retail Customer Service 🏬
-
Product Recommendations: The chatbot retrieves the best product matches for customer queries.
-
Accurate Information: With real-time retrieval, it ensures responses are relevant and up-to-date.
-
Improved Customer Satisfaction: By combining retrieval and generation, RAG enables a smoother and more helpful customer experience.
Recap: From Memory to Mastery — How RAG Enhances AI’s Capabilities 🧠🔍
In this chapter, we explored the foundations of Retrieval-Augmented Generation (RAG), focusing on its core components — embedding models, vector databases, and language models — and how they work together to create more accurate and context-aware responses. We also discussed alternative models and databases that cater to different use cases, making RAG a versatile solution across industries.
The power of RAG lies in its ability to blend semantic understanding with real-time retrieval, offering more precise answers, dynamic adaptability, and scalability.
Up next, 🌍 Real-World Magic — How RAG Transforms Industries ✨🚀, we’ll dive deeper into practical applications of RAG across various sectors. We’ll explore how RAG revolutionizes fields like customer service, healthcare, e-commerce, and more, highlighting its transformative impact and showcasing a retail chatbot example that brings these concepts to life.